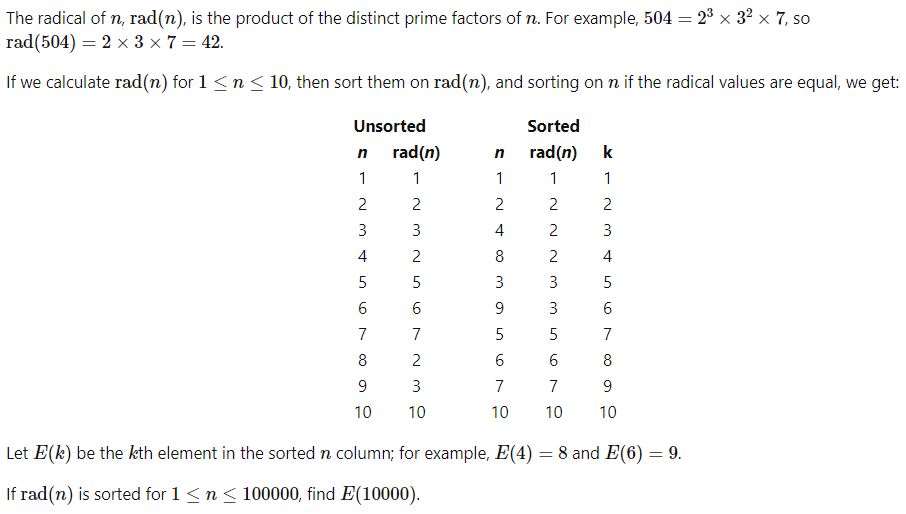
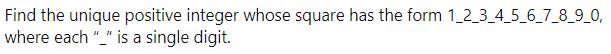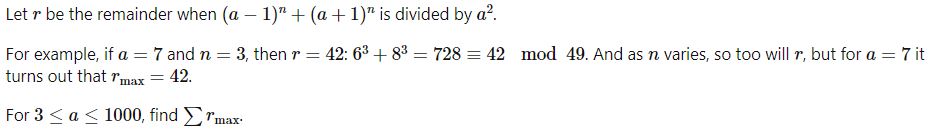문제에서 요구하는 대로 구성하면 프로그램의 구조는 간단하다. 2를 계속 곱해가면서 L로 시작되는 n번째 숫자를 찾아 거듭제곱수를 알려주면 된다.
이렇게 구현하면 예시로 나와있는 p(12,1), p(12,2), p(123,45)는 어렵지 않게 구할 수 있다. 하지만, 2의 거듭제곱수 중에서 123으로 시작하는 678910번째 숫자가 2의 몇 거듭제곱인지 찾는 것은 데이터 허용범위가 넓은 파이썬으로도 어려운 일이었다. (이번에는 4300자릿수 이상을 넘을 수 없다는 에러메시지를 봤던 것 같다)
프로젝트 오일러의 높은 번호 문제는 난이도가 낮아도, 간단히 해결 가능한 것이 아니라 (주로 상상도 못한 크기의 숫자로) 한계가 숨어 있고, 이것을 어떻게 해결해내는 것인지가 추가로 포함되어 있는 것 같다.
이번 문제에서는 앞의 3자리만 동일하면 되기 때문에, 일정크기 이상으로 커지면 앞의 3자리에 영향을 미치지 않을 아랫쪽 수를 10000으로 나눠 없애는 형태로 계산했는데, 정확한 숫자를 구하는 것이 아니어서 살짝 걱정되었지만 맞출 수 있었다.
처음에는 기계적으로 중복순열을 만들어서 해결하려 했으나, 1016크기의 중복순열을 만들면서 메모리 에러가 발생했다.
그래서 격자의 (0,0)에서 (4,4)까지 a부터 p까지 자리기호를 매기고, (16차) 반복문으로 생성되는 숫자를 기준으로 첫 행의 가로 합계(sum=a+b+c+d)가 나머지 가로 합계(e+f+g+h, i+j+k+l, m+n+o+p), 세로 합계(a+e+i+m, b+f+j+n, c+g+k+o, d+h+l+p), 대각선(a+f+k+p, d+g+j+m)과 동일한 지 확인하도록 구성을 했는데, 1016 크기만큼 반복을 하면서 시간이 대책없이 오래 걸리는 문제가 발생했다.
그래서, 고민을 하다 다른 사람이 해결한 방법을 검색해 봤는데, 변수 갯수를 줄이는 형태로 접근해서 실행시간을 개선하는 방법을 제시한 것이 있어 그 방법을 적용해 봤다. 앞 문단에서 설명한 것과 마찬가지 상황에서 sum=a+b+c+d로 했을 때, 가로 세로 합계 공식을 바꿔, h=sum-e-f-g, l=sum-i-j-k, p=sum-m-n-o, m=sum-a-e-i, n=sum-b-f-j, o=sum-c-g-k를 구할 수 있고, 대각선 공식을 이용하면 j=sum-d-g-m이 된다.
a, b, c, d, e, f, g, i, k에 대해 반복문을 구성하여, h, o는 반복문의 값으로 구하고, m을 먼저 구해서 j를 구하고, 그 값을 이용해서 l, p, n를 구할 수 있다. 대각선의 합계가 맞는지 확인하고(sum=a+f+k+p), 연산에 의해 구해진 값(h,j,l,m,n,o,p)이 0~9 사이의 값인 경우에 문제의 조건을 만족하는 경우가 된다.
이것을 반복문을 활용해서 계속 구해나가면 복잡도가 1016에서 109로 1/107이 줄어들어, 이전보다는 훨씬 빠르지만 그래도 답을 구하는 데는 시간이 좀 필요했다. 다만, 스스로 생각해서 끌까지 해결하지 못하고 다른 사람의 아이디어를 봐야 해결가능하다는 것이 씁쓸했다.
약분되지 않는 분수를 학교에서는 기약분수(inreducible fraction)로 배웠는데, 여기에서는 무슨 차이가 있는지 모르겠지만 탄력분수로 정의하고 있다.
처음에는 모든 숫자를 대입해서 계산을 시도했는데, 시간이 너무 많이 걸렸다. 기약분수가 적은 경우를 찾는 형태여서 생각해보니 69번 문제를 변형한 문제처럼 보였다.
일단 많이 나눠주는 수의 곱으로 분모가 되어야 작아질 것이기 때문에 처음에는 짝수를 대상으로 시도했는데, 결과값 패턴을 보니 2와 3의 공배수인 6의 배수가 값이 작은 것이 보였다. 가만히 생각해보니 작은 소수의 곱으로 구성되는 숫자일수록 나눠지는 숫자가 많아 정답에 근접하게 나오게 되는 패턴을 찾았다.
그래서, 일단은 2에서 시작해서 나오는 소수의 곱을 대상으로, 배수를 5번씩 계산해서 정답보다 낮은 경우를 찾도록 했다.(예를 들어, 2의 경우 2,4,6,8,10, 2와3의 곱인 6의 경우 6,12,18,24,30, 2와3과5의 곱인 30의 경우 30,60,90,120,150 등을 계산하도록 했다)
소수의 곱은 생각보다 기하급수로 커졌고, 그 덕분에 정답 또한 생각했던 것 보다는 엄청 큰 값이었고, 답에 근접한 값만 계산하게 했어도 상당한 시간이 필요했다.
일단 19자리 숫자이면서 1의 자리에 0, 백 자리에 9, 만 자리에 8, 백만 자리에 7, 억 자리에 6, 백억 자리에5, 조 자리에 4, 백조 자리에 3, 경 자리에 2, 백경 자리에 1이 들어가는 숫자를 구하면 되는데, 첫 자리가 1로 시작하므로 제곱하여 백경이 되는 1,000,000,000부터 시작할 것이고, 첫 자리가 2보다 작아야 하므로 √2*1,000,000,000 보다는 작아야 할 것이다.
그리고, 1의 자리가 0이므로 마지막 숫자는 0이 되므로 이 사이의 숫자를 반복문을 통해 계산해서 어렵지 않게 구할 수 있었다.
등차수열이기 때문에 처음에는 x를 기준으로, x2-(x-a)2-(x-2a)2=n으로 수식을 만들어서, 정리하니 x2-6ax+5a2=-n이어서, (x-a)(x-6a)=-n이 되었다. 모양은 좀 이상했지만 처음 값 x와, 차이 a 기준으로 n의 약수의 곱이 된다는 것을 알 수 있었다.
(제대로 접근한 사람은 가운데 y를 기준으로 (y+a)2-y2-(y-a)2=n으로 수식을 만들어서, 전개하면 4ay-y2=n이 되고, 차이 a 기준으로 정리하면 a=(n+y2)/4y가 된다)
처음에는 약수의 갯수만 관련이 있다고 생각하고 약수가 20개 인 수(두 수의 곱이므로 절반인 10개의 해답을 만드는 수로 추정)의 갯수를 찾도록 구현했는데, 약수 만드는 함수의 성능이 나빠서 시간이 너무 많이 걸리고, 이를 개선해서 조금 빨리 돌아가도록 했는데 오답이 나왔다.
다시 확인해보니, 후보가 되는 것은 약수가 맞지만 두 약수의 곱이 아니기 때문에 약수를 대상으로 등차수열 조건(a=(n+y2)/4y, a<y, a는 정수)을 만족하는지 확인해야 되는 것이었다. 그렇게, 단순히 약수의 갯수를 세는 것이 아니라 약수를 대상으로 등차수열을 만들 수 있는 것이 몇 개인지 확인하도록 변경해서 답을 구할 수 있었다.
그리고, 처음에는 n의 약수를 1~n/2까지 비교하도록 되어 있던 함수 성능을 개선한 이후에야 수분 내에 답을 구할 수 있어서, 성능의 중요성을 다시 한 번 느꼈다.
기존에는 검증 대상이 되는 숫자에서 2의 배수, 5의 배수를 제외했지만, 소수 목록을 만들어서 소수를 검증 대상에서 제외하는 과정을 추가하고, n-1을 A(n)으로 나눠지는 숫자를 찾으면 된다.
문제에서 요구한대로 코딩했는데도 처음에 오답이 나와 원인을 분석하는 데 시간이 조금 걸렸다. 원인을 찾아보니, 검증대상에서 제외할 소수목록을 1만 이하의 숫자를 대상으로 만들었는데 실제로는 1만 이상의 숫자까지 대상이 되면서, 제외되어야 하는 소수가 목록에 포함되었던 것이 문제였다.
문제를 조금 부연설명하면 gcd(n,10)=1이라 했으므로, n은 2, 5와 공약수가 없는 숫자이다(2와 5로 나눠지지 않는다). 이것만 가지고 구현했을 때 예시에서 나온 A(7), A(41)이나 결과가 10이 넘는 A(n)의 값은 쉽게 구할 수 있는데, 결과가 1백만을 초과하는 것을 구하려면 시간이 대책없이 필요했다.
처음 2부터 입력해서 나온 n, k의 결과값 목록을 보면서도 생각하지 못했는데, 오일러 프로젝트를 풀고 있는 다른 블로거의 설명을 보고 빨리 해결하는 방법을 구할 수 있었다.
중요한 단서는 k가 n보다 클 수 없다는 것이다. 그것을 보고 시작지점을 변경해서 빠른 시간 내에 답을 구할 수 있었다.
회문은 4번 문제에서 처음 나온 이후에 오일러 프로젝트에 몇 번 나온 문제이고 여기까지 풀었으면 함수로도 가지고 있을 것이다.
일단 문제에서 요구한 대로 구현해 봤다. 1은 제외한다고 했으므로 2에서 1억까지 올라가면서 회문에 해당하는 숫자를 대상으로, 각 숫자가 연속된 제곱수의 합계로 나타낼 수 있는지 판별하는 것이다. 이를 위해 제곱수의 목록을 만들어두고 시작하는 자리를 이동해가면서 차례로 합해나가는 과정을 반복하도록 하고, 제곱수가 비교할 숫자보다 크면 그 수에 대해서는 검증을 중단하도록 했다.
실행해보니 처음에는 빠르지만 천만이 넘어가면서 실행속도가 엄청나게 느려지는 것이 보였다. 하지만 조금 기다려주면 끝이 나는 수준이어서 이렇게 해결하기로 했는데, 제곱수를 1억까지 만들었다가 그것이 넘는 경우가 필요해지면서 거의 마지막에 리스트의 인덱스 에러가 생기고 결과를 확인하지 못했다. 제곱수 리스트를 조금 더 크게 만든 후에 답을 구할 수 있었다.
하지만, 다른 사람은 어떻게 접근했는지 확인했을 때, 정반대로 접근하는 것이 있었는데 빠른 해결을 위해서는 좋은 방법 같아서 아이디어를 적는다. 접근을 반대로 해서, 1만의 제곱이 10억이므로, 1만 이하의 제곱수 목록을 만들고 각 숫자를 연속해서 나오는 결과 목록을 생성한 후에, 이 중 회문인 것만 답으로 선택하는 방법이다. 실험삼아 구현해봤는데, 결과 목록을 만드는 데 생각보다 많은 시간이 걸려 큰 차이가 나지 않을 것 같았다.
가방에 붉은 색 원반 1장과 푸른 색 원반 1장이 있다. 게임에서 원반 1장을 랜덤하게 꺼내고 색을 기록한다. 각 회차가 끝나고 나면 원반을 다시 가방에 넣고 붉은 색 원반 1장을 추가한 후, 원반 1장을 랜덤하게 꺼낸다.
참가자는 1파운드를 내고 경기에 참가하고, 게임이 끝났을 때 푸른 색 원반이 붉은 색 원반보다 많은 경우 승리한다.
게임이 4회차로 구성된 경우, 참가자가 승리할 확률은 정확하게 11/120이고, 주최측이 손실을 입지 않으려면 할당해야 하는 최대 상금은 10파운드가 되어야 한다. 모든 상금은 파운드 단위로만 되어야 하고 참가비 1파운드가 포함되므로, 예시에서 참가자가 획득하는 돈은 9파운드가 된다.
예시를 조금 설명하면, 참가자가 승리하는 경우는 파란색 4장을 꺼낸 경우와 3장을 꺼낸 경우이다. 그러면 전체 가능한 경우 120(2*3*4*5) 중 파란색 4장을 꺼낸 경우는 1회이며(1/2*1/3*1/4*1/5), 3장을 꺼낸 경우는 10회(처음 나올 경우 1회, 2번째 2회, 3번째 3회, 4번째 4회)가 된다.
15회차 게임에서 승리할 경우는 전체 경우 20,922,789,888,000(2*3*4*5*6*7*8*9*10*11*12*13*14*15*16) 중 파란색을 8장 이상 꺼낸 경우를 계산하면 된다. 위 예시 설명에서 나오듯이 파란색을 꺼내는 경우는 1, 붉은색을 꺼내는 경우는 '해당 차수 원반 전체-1'이 된다.
붉은 색인 경우를 대상으로 계산을 하면 되므로, 붉은 색이 0장에서 7장인 경우를 계산하는 반복문을 만들고, 각 반복에서 가능한 조합을 생성해서 조합의 갯수를 합하는 형태로 구성하였다. 참고로, 붉은색 공이 2개인 경우 2개를 곱하는 방식을 통해 조합의 전체 갯수를 구하고, 조합의 갯수를 합해야 한다.
그리고, 참가자가 우승할 조합 갯수에 상금을 곱해서 전체 경우보다 작으면서 가장 큰 상금을 구하면 된다.
조합이나 확률을 잘 이해하면 좀 더 짧은 코드로 구현 가능했을 것 같은데, 기초만 이해하는 상황에서는 이 구성이 최선이었고 빠른 시간 내에 답을 구할 수 있었다. 난이도는 35%였지만 적성에 맞는 문제인지 어렵지 않게 해결 가능했다.
처음에는 brute force에 가까운 방법으로 접근했는데, 시간 문제가 생겼다. 즉, 10부터 1씩 키워나가며 자리수의 합을 구하고, 자리수의 합에 대해 거듭제곱을 하면서 원래 숫자가 만들어지는지 확인하는 방법이었는데, 예시로 제공한 10번째 숫자까지는 비교적 빠른 시간 내에 구했지만, 그 이후로는 숫자가 기하급수적으로 커지면서 10분 이상이 지나도 답이 나오지 않는 상황이 되었다.
그래서, 다른 사람은 어떤 식으로 접근했는지 찾아봤는데, 파이썬이 큰 수를 다루는 데 유리한 점을 이용하여 해결했다는 것이 있어서 그것을 참조해서 해결했다. for 반복문 2개를 이용해서 일정크기 이내의 밀과 지수에 대한 거듭제곱을 만들어서, 거듭제곱 각 자리수의 합이 밑과 동일한 경우를 구하는 방법이다. 그 이후에는 정렬하고, 30번째 요소를 찾으면 되는 것이다.
만약, 찾은 것이 정답이 아니면 밑을 충분히 크게 만들지 않았기 때문에 밑의 반복범위를 키우고, 그래도 안되면 거듭제곱의 반복범위를 키우는 방법으로 접근하면 어렵지 않게 구할 수 있을 것이다. 생각하기에 따라 상당히 위험한 방법의 brute force이지만 파이썬이 큰 숫자를 다루는 데 문제가 없기에 가능한 방법이었던 것 같다.
어떤 양의 정수 n은 [n+reverse(n)]의 모든 숫자가 홀수로만 이뤄지는 속성이 있다. 예를 들어, 36+63=99이고 409+904=1313이다. 이런 숫자를 가역숫자(reversible number)라 한다. 36과 63, 409와 904는 가역숫자이다. 0으로 시작하는 경우는 n, reverse(n)에 허용되지 않는다.
문제에서 0으로 시작하는 경우를 허용하지 않는다고 했으므로, 끝이 0인 숫자는 가역 여부를 확인할 필요가 없다. 프로그램의 구성은 비교적 간단한데, 10억까지 계산을 해야되기 때문에 시간이 많이 소요된다. 이것을 줄일 방법이 있는지 모르겠지만 일단 시도해 봤다.
10억까지 반복하면서, 각 숫자의 순서를 바꾸고 더해서, 모든 자릿수가 홀수인지 확인하면 된다. 10이하의 숫자는 무조건 짝수가 되기 때문에 고려하지 않았다. 1억까지 구하는데 10분 넘는 시간이 걸렸고, 숫자가 커지면서 조금씩 시간이 늘어나 10억까지는 100분 넘게 걸려 답을 구할 수 있었다.
가만히 생각해 보니, 10이하 숫자를 고려하지 않았던 것처럼, 9자리 숫자도 n+reverse(n)을 하면 모두 홀수가 되지 않는다. 가운데인 5번째 숫자는 같은 숫자를 2번 더하기 때문에 무조건 짝수가 되고, 그것을 막으려면 6번째 숫자가 10이 넘어야 한다. 그러면 4번째 숫자도 10이 넘어서, 7번째 숫자가 홀수이면 3번째 숫자도 홀수인 경우 4번째 숫자에서 1이 넘어오기 때문에 (3번째와 7번째) 둘 중 하나는 짝수가 될 수 밖에 없다. 그러다보니, 전체 연산시간의 90% 이상을 차지하는 1억 이상의 숫자 모두가 가역숫자가 되지 못하는데 계산하느라 시간을 낭비한 꼴이 되어버렸다.
다른 분이 이야기한 아이디어(양변에 nxy를 곱해서 분모 없애기)를 참고해서 해결할 수 있었다.
문제에 나오는 공식의 분모를 없애기 위해 간단히 수학을 적용해서 양변에 xyn을 곱하면 ny+nx=xy가 된다. 그리고, 예시를 보면 짐작 가능하겠지만 n이 x, y보다는 작기 때문에 x를 n+a, y를 n+b로 바꾸면 n(n+b)+n(n+a)=(n+a)(n+b)가 된다. 이를 풀면 n2+nb+n2+na=n2+na+nb+ab가 되고 양변을 정리하면 n2=ab가 된다.
이 특성을 이해하고, 예시를 다시 보면 x의 값이 n=4일 때, n보다 1, 2, 4만큼 큰 것을 알 수 있다. 이것이 4의 약수이기 때문에, 솔루션이 1000개를 넘는 것은 약수가 1000개를 넘는 경우와 같은 것으로 이해되었다. 그래서, 먼저 풀었던 243번 문제에서 적용한 소수의 곱을 대상으로 배수로 키워나가면서 약수가 1000개 이상인 경우를 찾는 방법을 적용했는데, 예상과는 달리 오답이었다.
n2=ab를 다시 생각해보니, n의 약수가 아니라 n2의 약수 중 n이하의 값인 것들을 찾으면 되는 것이었다. 예시로 나온 4가 너무 작은 수이면서 2의 배수여서 다양한 경우가 나오지 않아 잘못된 유추를 하게 되었던 것이다.
약수를 구하는 함수를 n제곱을 입력값으로 해서 n이하의 값만 구하도록 바꾸고 나니 빠른 시간 내에 답을 구할 수 있었다.
어렵지 않아 보이지만 실행 시간이 많이 소요되는 문제이다. 나누는 수가 a2이기 때문에 나머지를 확인하기 위해 검증하는 범위를 a2번까지 설정해야 했기 때문이다.
그리고, 나머지 함수의 특성을 살려서 적용해야지 문제에서 제시한 그대로 코딩했을 때에는 숫자가 기하급수적으로 커지면서 실행시간이 매우 많이 필요하게 되었다.
나머지 함수의 곱셈 특징((a*b)%c=(a%c)*(b%c))을 활용하여, 거듭제곱의 경우 분산해서 계산하도록 코드를 개선했다. 즉, a7=a*a2*a4, a9=a*a8과 같은 형태로 나누고, 각각에 나머지 함수를 적용해서 숫자가 최대한 커지지 않도록 만들었다.
그렇게 개선했어도 실행시간은 많이 필요했으며(100까지 7초, 200까지 58초, 300까지 173초, 400까지 360초, 500까지 628초, 600까지 942초, 700까지 1365초, 800까지 1777초, 900까지 2415초, 1000까지 3043초로 총 3시간 필요), 이 방식보다는 좀 더 빠른 형태의 수학에 기반한 해법이 있을 것 같다.
한 자리 숫자는 증가, 감소, bouncy가 있을 수 없으므로 10부터 시작해서 솟자를 계속 키워나가면서 증가수, 감소수, bouncy number를 판별하게 구성하면 된다.
구성할 때 한 가지 고려할 것은 이전 숫자와 값이 같으면 아직 증가수인지 감소수인지 판별을 유보해야 한다는 것이다. 처음에 이 부분을 잘못 생각하고 유보할 때 증가수, 감소수 플래그를 무조건 True로 값을 넣도록 프로그램을 만들었는데, 3자리에서는 유효하지만 4자리 숫자에서 오류를 만들게 되어 있어서 판별할 숫자를 50%만 제시했으면 이유를 찾지 못할뻔 했다. (값이 같을 때 이전에 증가수/감소수로 판별된 경우 이전 판별을 유지해야 되는데 잘 못 생각해서 계속 유보하게 만든 것이 문제였다)
해결할 아이디어가 떠오르지 않아 찾아보니 고1 정도의 수학 지식을 필요로하는 문제였다. 벡터를 이용, 삼각형 면적 이용, 도형(삼각형)과 교차하는 점의 갯수, 무게중심좌표 등 해결하는 방법은 몇 가지가 있는데 개념은 알겠는데 실제 어떤 형태로 구현할 것인지는 쉽지 않았다.
이 중 무게중심좌표(Barycentric Coordinate System)를 이용한 해법으로 답을 구했다. 삼각형 세 꼭지점의 좌표를 (x1,y1), (x2, y2), (x3, y3)라 하고, 원점을(xp, yp)라 할 때, 다음과 같이 세 좌표를 계산해서 모두 0보다 크면 삼각형 내부에 있다고 한다.
그리고, 왜 이렇게 난이도가 올라갈까 싶었는데, 게임을 할 때 특정 좌표가 도형 내에 있는지 밖에 있는지 판단하는 방법으로 이 코드를 사용할 수 있다고 한다. 좌표가 보호막 내에 있는지 판단하거나, 게임 내의 비행체와 총알의 충돌을 판단하는 등에 사용할 것을 생각하면 이해가 필요한 것 같다.
프로젝트 오일러의 문제를 100번까지 모두 해결하는 것을 목표로 진행했는데, 몇 문제는 아이디어가 잘 떠오르지 않아 아직 해결하지 못했다. (특히 68번은 문제 자체를 이해할 수 없어 어떤 식으로 접근해야 할 지 오리무중이다) 이제는 난이도를 중심으로 해결되는 대로 포스팅할 예정이다.
100번대 이후 문제를 풀어보니, 난이도 5%도 문제대로 하면 코딩은 간단하지만 말도 안되는 수준으로 실행시간이 많이 필요하게 되어, 수학지식을 바탕으로 최적화하기를 요구하고 있는 등 적절한 방법으로 해결하는 것이 쉽지 않았다. 이제는 진짜 파이썬 공부인지 수학 공부인지 알 수 없어지는 상황이 되었지만, 그래도 최대한 해결해 볼 예정이다.
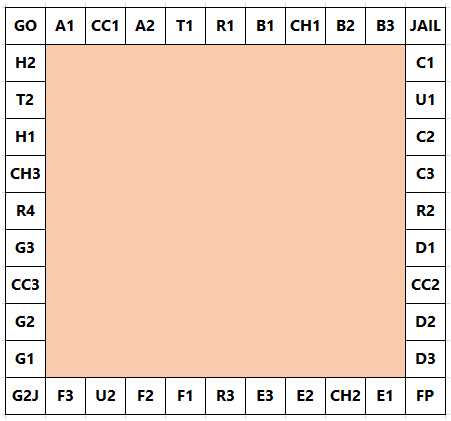
In the game,Monopoly, the standard board is set up in the following way:
A player starts on the GO square and adds the scores on two 6-sided dice to determine the number of squares they advance in a clockwise direction. Without any further rules we would expect to visit each square with equal probability: 2.5%. However, landing on G2J (Go To Jail), CC (community chest), and CH (chance) changes this distribution.
In addition to G2J, and one card from each of CC and CH, that orders the player to go directly to jail, if a player rolls three consecutive doubles, they do not advance the result of their 3rd roll. Instead they proceed directly to jail.
At the beginning of the game, the CC and CH cards are shuffled. When a player lands on CC or CH they take a card from the top of the respective pile and, after following the instructions, it is returned to the bottom of the pile. There are sixteen cards in each pile, but for the purpose of this problem we are only concerned with cards that order a movement; any instruction not concerned with movement will be ignored and the player will remain on the CC/CH square.
Community Chest (2/16 cards):
Advance to GO
Go to JAIL
Chance (10/16 cards):
Advance to GO
Go to JAIL
Go to C1
Go to E3
Go to H2
Go to R1
Go to next R (railway company)
Go to next R
Go to next U (utility company)
Go back 3 squares.
The heart of this problem concerns the likelihood of visiting a particular square. That is, the probability of finishing at that square after a roll. For this reason it should be clear that, with the exception of G2J for which the probability of finishing on it is zero, the CH squares will have the lowest probabilities, as 5/8 request a movement to another square, and it is the final square that the player finishes at on each roll that we are interested in. We shall make no distinction between "Just Visiting" and being sent to JAIL, and we shall also ignore the rule about requiring a double to "get out of jail", assuming that they pay to get out on their next turn.
By starting at GO and numbering the squares sequentially from 00 to 39 we can concatenate these two-digit numbers to produce strings that correspond with sets of squares.
Statistically it can be shown that the three most popular squares, in order, are JAIL (6.24%) = Square 10, E3 (3.18%) = Square 24, and GO (3.09%) = Square 00. So these three most popular squares can be listed with the six-digit modal string: 102400.
If, instead of using two 6-sided dice, two 4-sided dice are used, find the six-digit modal string.
표준 보드 게임인 '모노폴리'는 위 그림과 같이 구성된다.
플레이어는 GO에서 시작하고, 육면체 주사위 2개를 굴려 나온 값만큼 시계방향으로 진행한다. 추가 규칙이 없으면 각 자리를 방문할 확률은 2.5%로 동일하다. 그러나, G2J(감옥으로 가시오), CC(보물상자), CH(기회)를 방문하면 확률은 바뀐다.
G2J를 방문하거나, CC, CH에 있는 한 장의 카드를 뽑으면 플레이어는 감옥으로 가야한다. 플레이어가 같은 숫자를 3번 연속으로 굴리지 못하면, 3번째 굴린 결과까지는 진행하지 못하고, 감옥으로 곧장 가게 된다.
게임을 시작할 때, CC, CH카드는 섞어 둔다. 플레이어가 CC, CH에 도착하면 각 파일 가장 위에 있는 카드를 뽑아, 지시사항을 따르고, 뽑은 카드는 가장 파일 가장 아래에 둔다. 각 파일에는 16개 카드가 있지만, 이번 문제의 목적을 위해 이동을 명령하는 카드만 고려하고, 이동과 관련없는 카드는 무시되고 플레이어는 CC/CH 자리에 남아있게 된다.
보물 상자 (2/16 카드):
GO로 이동하시오
감옥(JAIL)으로 가시오
기회 (10/16 카드):
GO로 이동하시오
감옥(JAIL)으로 가시오
C1로 가시오
E3으로 가시오
H2로 가시오
R1로 가시오
다음 R(열차 회사)로 가시오
다음 R로 가시오
다음 U(전력(utility) 회사)로 가시오
3칸 뒤로 가시오
이번 문제의 핵심은 특정 자리를 방문하게 될 것을 고려하는 것이다. 즉, 주사위를 굴린 후 특정 자리를 끝낼 확률을 말한다. 이런 이유로 끝낼 확률이 0인 G2J를 제외하고, CH는 5/8이 다른 자리로 이동하게 하므로 가장 낮은 확률을 가지고, 플레이어가 각 롤을 끝낼 때 우리가 관삼가지는 마지막 자리이다. 우리는 감옥의 단순 방문과 감옥으로 보내는 것에 차이를 두지 않을 것이고, 다음 순서에 나오기 위해 지불할 것이라 가정하고 "감옥에서 나오기 위한" 같은 숫자를 요구하는 규칙 또한 무시할 것이다.
GO에서 시작해서 각 자리에 번호를 00에서 39까지 매기면, 대응하는 자리 집합을 2자리 문자열을 결합하여 만들수 있다.
통계적으로, 가장 인기 있는 자리 3개를 순서대로 보면, 10번 자리인 감옥(6.24%), 24번 자리인 E3(3.18%), 0번 자리인 GO(3.09%)이다. 이 셋은 가장 인기있는 자리이고 6자리 숫자로 표현하면 102400이다.
육면체 대신 사면체 주사위를 굴릴 경우 (가장 인기있는 3자리를 결합한) 6자리 숫자를 구하시오.
부루마불이라 부르는 모노폴리를 단순화하여 문제를 만든 것인데, 문제에서 요구한 조건을 정리하면 다음과 같다.
주사위 결과에 따라 이동하는데, 같은 숫자가 3번 나오면 감옥으로 이동, 보물상자(CC)와 기회(CH)에서는 뽑은 카드 결과에 따라 이동, G2J에 가면 감옥으로 이동한다. 그 외 모노폴리에 있는 부동산 구매 등은 생략하고 이동 중심으로만 했으며, 감옥을 빠져나오는 조건도 따로 두지 않았다.
가장 많이 방문하는 3곳을 구하라는 것인데, 어떻게 할 것인지 고민하다가 주사위 2개를 랜덤하게 굴리는 형태로 많은 횟수를 실제 게임을 해서 방문하는 장소를 카운트하는 형태로 구하기로 했다. 나중에 찾아보니 이것을 몬테 카를로 방법이라 부른다고 한다.
여기까지 정리되고 나니 구현하는 것은 그렇게 어렵지 않았다. 다만, 기본값 설정 등에 있어 명확하게 하지 않은 부분에서 잘못 동작되어 처음에는 오답이 나왔었다.
If a box contains twenty-one coloured discs, composed of fifteen blue discs and six red discs, and two discs were taken at random, it can be seen that the probability of taking two blue discs, P(BB) = (15/21)×(14/20) = 1/2.
The next such arrangement, for which there is exactly 50% chance of taking two blue discs at random, is a box containing eighty-five blue discs and thirty-five red discs.
By finding the first arrangement to contain over 1012= 1,000,000,000,000 discs in total, determine the number of blue discs that the box would contain.
파란색 디스크 15장, 빨간색 디스크 6장으로 구성된 21장의 디스크가 있는 박스에서, 디스크 2장을 랜덤하게 선택하는 경우 2장의 파란색 디스크를 선택할 확률은 P(BB)=(15/21)x(14/20)=1/2이다.
동일한 구성으로 2장의 파란색 디스크를 랜덤하게 선택할 확률이 50%인 경우는 85장의 파란색 디스크와 35장의 붉은색 디스크로 구성된 경우이다.
총 1012= 1,000,000,000,000장 이상 디스크가 있을 때 동일한 구성으로 2장의 파란색 디스크를 랜덤하게 선택할 확률이 50%가 되는 경우는, 파란색 디스크가 몇 장 있을 때인가?
(중학생 이하 수준이지만) 갈수록 수학문제가 되고 있는 상황인데, 근의 공식을 이용하여 해결하기로 결정했다. 이전에 √를 바로 사용하면서 소숫점이 이하 자리 숫자가 있음에도 값이 너무 작아 정수로 판정되는 오류를 겪었기 때문에, 큰 수이지만 일단 제곱수인 상태에서 적용해 보기로 했다.
확률이 1/2일 때 총 디스크 수를 c, 파란색 디스크 수를 x라고 하면, P(BB)=(x/c)*((x-1)/(c-1))=1/2이며, 이것을 전개하면 2x2-2x=c(c-1), 2x2-2x-c(c-1)=0이 된다. 여기에 근의 공식을 적용하면 x=(2+(4+4*2*c(c-1))**0.5)/2*2가 되고, 루트 기호 부분 기준으로 정리하면 (4+8c(c-1))**0.5=4x-2이 되고, 양쪽을 제곱하여 루트를 없애면 1+2c(c-1)=(2x-1)2가 된다. 수학 기호를 html로 표기하는 방법이 익숙하지 않아 가독성이 나쁘게 적었지만 이와 같은 형태로 방정식을 구할 수 있다.
여기에서 c는 1조에서 시작하고, x는 좌변의 값보다 조금 작은 값이 나올 값에서 시작해서 양 변이 같을 때까지 c와 x값을 계속 키우면서 찾는 작업을 했다. 양변을 크게 보면 8*c^2와 16*x^2가 있어서 x의 시작값을 1부터 하지 않고 c/√2부터 시작해서 추적했다. 실행이 생각보다 오래 걸려서 상황을 보니 이 방법으로는 답을 구할 수 없을 것 같았다.
먼저 방법으로는 해결되지 않아 인터넷을 검색해 보니, 연분수와 비슷하게 x, c의 이전값을 통해 새 값을 찾을 수 있다고 되어 있었다. 문제에서는 (x, c) 값이 (15, 21), (85, 120)인 경우가 있었는데, (3, 4)인 경우에도 확률이 파란색 2개가 연속으로 나올 확률은 1/2가 된다.
이 (x,c)값 3쌍을 이용하여 x, c값의 다음 항에 대한 일차방정식을 유추해봤고(xn=3x+2c-2, cn=4x+3c-3), 그 공식으로 만든 숫자로 다음 값인 (493, 697) 또한 파란색 2개가 나올 확률이 1/2임을 확인해서 해당 공식을 통해 빠른 시간 내에 답을 구할 수 있었다.
일차방정식을 빨리 유추하기 위해 엑셀을 사용했는데, 엑셀로는 12자리 이상 숫자를 확인할 수 없다는 것 또한 알게 되었다.